
Step 1: Understand the problem
The first step of an experiment is to undergo the process of Discovery, so that you can better understand the problem. We began to notice some particularly complex projects were struggling to meet deadlines.
When we took a look at the estimations data and the risk scores of individual issues, we found that while many issues were delivered close to the estimation timeframe, issues with higher risk scores were causing the projects to fall behind. Taking the risk score of these issues that ran significantly over their estimation time, we found issues with a score above eight involved too much uncertainty to estimate.
Step 2: Develop a hypothesis
Once we realised issues with risk scores above eight were too complex or unfamiliar for our developers to estimate, we hypothesised that we would need to add an allotment of time for them to experiment and research the issue before they could begin work. This is a Tech Spike.
Our hypothesis could be summarised as: If we include an allotment of time for a developer to experiment and research an issue with a risk score above eight, then our projects are less likely to run overtime, because we are removing some of the complexity or the developer’s unfamiliarity with the issue.
Step 3: Plan the experiment
To test our hypothesis, we decided to implement an allocation of time in our iterations that developers could draw upon to de-risk issues with a risk score above eight.
We decided to test this over the next two month’s worth of iterations to see if using a Tech Spike led to the overall iteration time being closer to the estimations.
Step 4: Collect the data
At the end of the experiment we found that developers were able to successfully draw on this bank of time to de-risk complex project issues. The average time needed in an iteration to do this was less than 10% of the overall iteration timeframe.
Step 5: Make a decision
Looking at the data we decided to implement a Tech Spike to help developers manage estimating particularly complex or unfamiliar issues. Tech Spikes set at an additional 10% of time to the overall iteration estimation, and can be drawn on by a developer in the following circumstances:
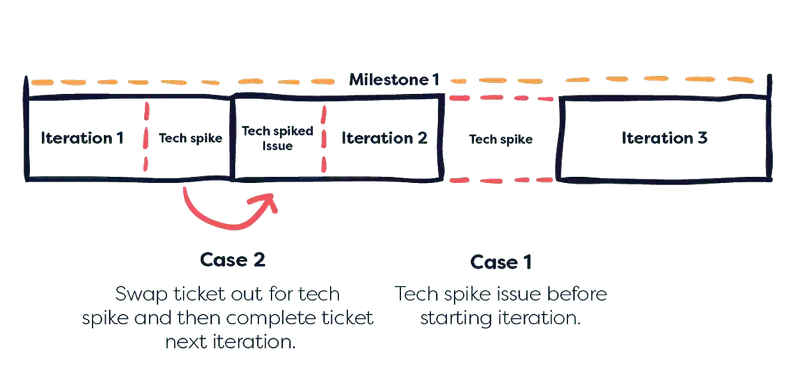
- If the issue being estimated has high priority and can’t be moved to another iteration, a tech spike can slot in before the next iteration as a chance to research before estimating.
- If the issue can be moved into a later iteration, a tech spike can be put into the next iteration in its place, to avoid interrupting the development flow.
Developers are particularly encouraged to use the time when an issue is found to have risk score over eight.
Future Work
Ultimately we need to continue to experiment with our estimations framework. While Tech Spikes improve how close our projects come to meeting our estimations, we intend to further experiment with how much time of an iteration needs to be allocated.
One area we hope to gain more evidence on is the minimum allocation of time we can allocate for Tech Spikes. We have started with a 10% multiplier. However we would like to find out if now that our companies experience has grown, we could be using a smaller amount of time in the iteration for Tech Spikes.
Another area for experimentation is whether, instead of using a multiplier for every iteration, Tech Spike time should be determined on an iteration by iteration basis in the estimations. Some iterations may have no high risk issues, yet are including the Tech Spike multiplier. Recently this has led to us delivering some iterations much quicker than estimated.
As we obtain more data in these areas we will continue to improve our Way of Working.

Written by Christine Chien
Marketing Operations and Partnerships
Our very own Christine is a marketer by day, nerd by night. If she isn’t developing our marketing strategy, she is usually found by her 3D printer or at a local plant shop.

